Kepler 模型服务器架构
机器翻译声明
本文档由 AI 语言模型 (Claude) 从英文自动翻译而成。如发现翻译错误或不准确之处,请在 Kepler 文档项目 中提交 issue 报告问题。
Kepler 模型服务器是 Kepler 的补充项目,促进功率模型训练和服务。这为 Kepler 提供了一个生态系统,可以从一个环境收集指标,使用管道框架训练 功率模型,并服务回另一个没有功率计(能量测量)可用的环境。
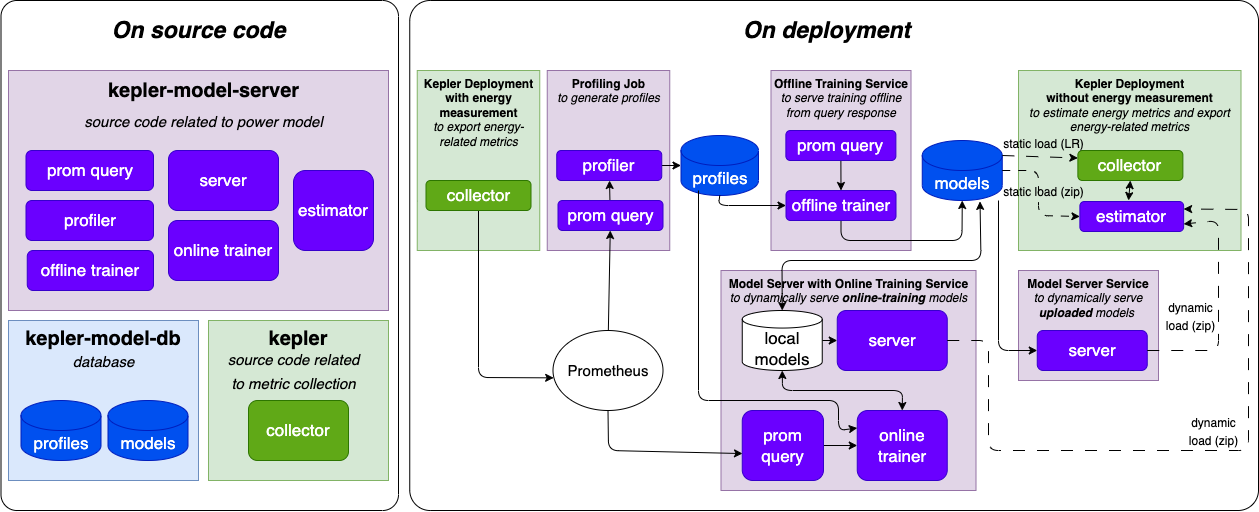
管道输入: 训练工作负载运行期间的 Prometheus 查询结果。
管道输出: 一个目录,包含由每个可用特征组训练的存档绝对和动态功率模型, 每个可用能源来源都有标签。
[管道名称]/[能源来源]/[模型类型]/[特征组]/[存档模型]
- 管道名称 不同建模方法组合的唯一名称,例如不同的提取器、隔离器、训练器集合、 支持的特征组和支持的能源来源。
- 能源/功率来源 功率标签的功率计来源。
- 模型类型 有或没有背景隔离的模型类型。
- 特征组 模型输入的利用率指标来源。
- 存档模型 格式为
[训练器名称]_[节点类型]的文件夹和 zip 文件,其中训练器 是训练解决方案的名称,例如GradientBoostingRegressor,node_type是用于训练的 服务器的分类配置文件。文件夹包含 - metadata.json
- 模型文件
- weight.json(本地估算器支持的模型(如线性回归 (LR))的模型权重)
- 特征工程 (fe) 文件
在 GitHub 上查看项目 ➡️ Kepler 模型服务器。