训练管道
机器翻译声明
本文档由 AI 语言模型 (Claude) 从英文自动翻译而成。如发现翻译错误或不准确之处,请在 Kepler 文档项目 中提交 issue 报告问题。
模型服务器可以为不同上下文和学习方法提供各种功率模型。训练管道是功率模型训练的 抽象,将一组学习方法应用于能源来源、功率隔离方法、可用能源相关指标的不同组合。
管道
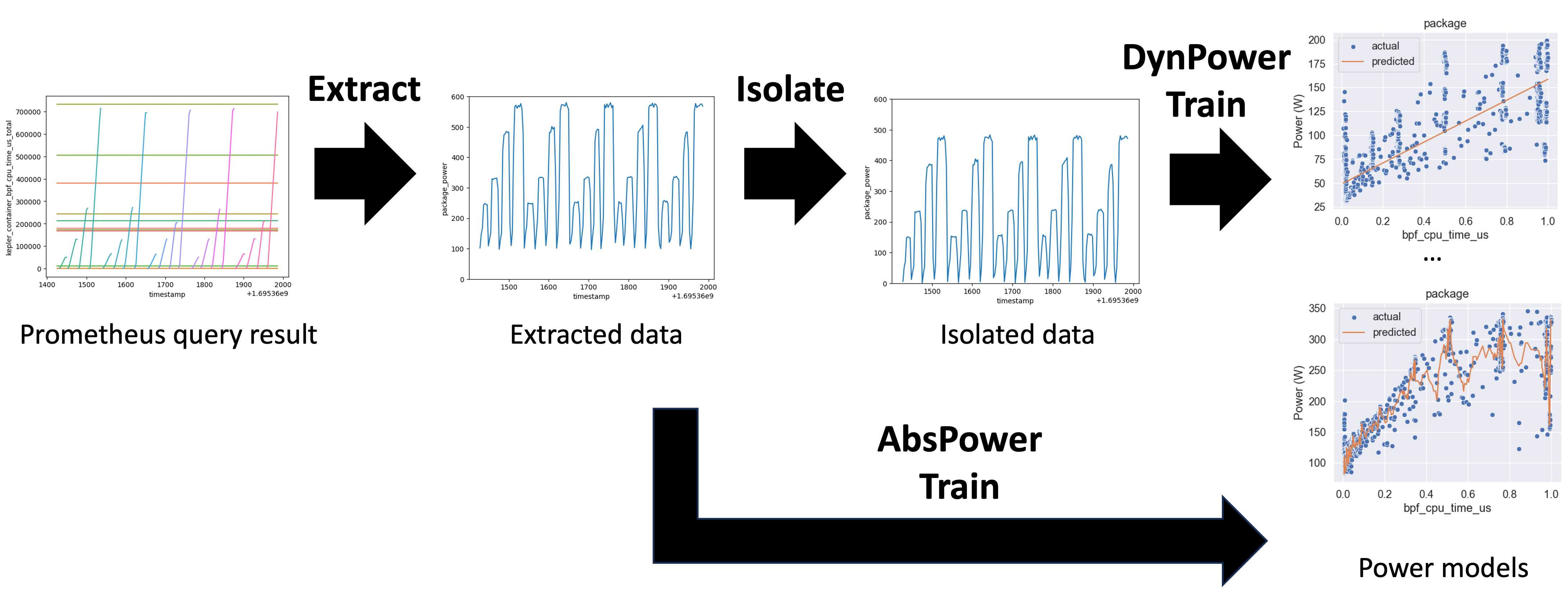
管道 由三个步骤组成:extract、isolate 和 train,如下所示。Kepler 将
能源相关指标导出为 Prometheus 计数器,提供随时间累积的数字。
extract 步骤是将计数器指标转换为计量指标,类似于 Prometheus rate() 函数,
给出每秒值。extract 步骤还为每个 特征组 单独清理数据。
从 Prometheus 查询检索的功耗是测量功率,由工作负载变化的功率部分(称为动态功率) 和即使在空闲状态下也消耗的功率部分(称为空闲功率)组成。
isolate 步骤是计算空闲功率并隔离每个 能源来源 的动态功耗。
train 步骤是应用每个 训练器 基于预处理数据创建功率模型的多种选择。
我们有一个路线图,为每个节点/机器类型单独应用管道构建功率模型。 在节点类型部分了解更多信息。
- 从能源来源部分了解更多关于
能源来源的信息。 - 从特征组部分了解更多关于
特征组的信息。 - 从功率隔离部分了解更多关于
isolate步骤以及相应的AbsPower和DynPower功率模型概念。 - 在训练器部分查看可用的
训练器。
能源来源 {#energy-source}
能源来源 或 来源 指提供能量数字的来源(功率计)。每个来源提供一个或多个
能量组件。目前支持的来源如下所示。
| 能源/功率来源 | 能源/功率组件 |
|---|---|
| rapl | package, core, uncore, dram |
| acpi | platform |
特征组 {#feature-group}
特征组 是基于基础设施上下文的可用特征的抽象,因为某些环境可能不公开某些指标。
例如,在私有云环境的虚拟机上,硬件计数器指标通常不可用。因此,为每个定义的
资源利用率指标组训练模型,如下所示。
| 组名 | 特征 | Kepler 指标来源 |
|---|---|---|
| CounterOnly | COUNTER_FEATURES | 硬件计数器 |
| BPFOnly | BPF_FEATURES | BPF |
| IRQOnly | IRQ_FEATURES | IRQ |
| AcceleratorOnly | ACCELERATOR_FEATURES | 加速器 |
| CounterIRQCombined | COUNTER_FEATURES, IRQ_FEATURES | BPF 和硬件计数器 |
| Basic | COUNTER_FEATURES, BPF_FEATURES | 除 IRQ 和节点信息外的所有 |
| WorkloadOnly | COUNTER_FEATURES, BPF_FEATURES, IRQ_FEATURES, ACCELERATOR_FEATURES | 除节点信息外的所有 |
| Full | WORKLOAD_FEATURES, SYSTEM_FEATURES | 所有 |
节点信息指来自 kepler_node_info 指标的值。
功率隔离 {#power-isolation}
从 Prometheus 查询检索的功耗是绝对功率,它是空闲功率和动态功率的总和(其中空闲 代表系统处于静止状态,动态是资源利用率的增量功率,绝对是空闲 + 动态)。此外, 这个功率也是所有进程的总功耗,包括用户的工作负载、后台和操作系统进程。
isolate 步骤应用一种机制将空闲功率从绝对功率中分离出来,产生动态功率。
它还涵盖了一个实现,用于分离后台和操作系统进程(称为 system_processes)
消耗的动态功率。
值得注意的是,即使用户工作负载的指标利用率为零,空闲和动态 system_processes
功率都高于零。
有两种常见的可用 隔离器:ProfileIsolator 和 MinIdleIsolator。
我们将使用隔离步骤训练的模型称为 DynPower 模型。同时,不使用隔离步骤训练的
模型称为 AbsPower 模型。目前,DynPower 模型不包括空闲功率信息,但我们计划
在未来包含它。
ProfileIsolator 依赖于在不运行任何用户工作负载的情况下收集特定时期的数据
(例如,功率和资源利用率)(称为配置文件数据)。这种隔离机制还从用于训练模型的
数据中消除了 system_processes 的资源利用率。
另一方面,MinIdleIsolator 识别训练数据中所有样本的最小功耗,假设这个最小
功耗代表空闲功率和 system_processes 功耗。
虽然我们也应该从用于训练模型的数据中移除最小资源利用率,但这种隔离机制在训练
数据中包括了 system_processes 的资源利用率。但是,我们计划在未来移除它。
如果存在与给定 node_type 匹配的 配置文件数据,管道将使用 ProfileIsolator
预处理训练数据。否则,管道将应用另一种隔离机制,例如 MinIdleIsolator。
(查看如何生成配置文件这里)
讨论
选择使用 DynPower 还是 AbsPower 模型仍在调查中。在某些情况下,DynPower
比 AbsPower 表现出更好的准确性。但是,我们目前利用 AbsPower 模型来估算
平台、CPU 和 DRAM 组件的节点功率,因为 DynPower 模型缺乏空闲功率信息。
值得一提的是,在公有云环境中的虚拟机上公开空闲功率是不可能的。这是因为主机的 空闲功率必须在主机上运行的所有虚拟机之间分配,而在公有云环境中无法确定主机上 运行的虚拟机数量。
因此,只有在节点上只有一个虚拟机运行(对于非常特定的场景),或者功率模型在 裸机环境中使用时,我们才能公开空闲功率。
训练器 {#trainer}
训练器 是一个抽象,用于定义应用于每个特征组和每个给定功率标记源的学习方法。
可用训练器 (v0.6):
- PolynomialRegressionTrainer
- GradientBoostingRegressorTrainer
- SGDRegressorTrainer
- KNeighborsRegressorTrainer
- LinearRegressionTrainer
- SVRRegressorTrainer
节点类型 {#node-type}
Kepler 根据其基准性能形成多组机器(节点),并为每组单独训练模型。识别的组
导出为 节点类型。